ML Model Training: Definition and Training Process
Machine Learning is an inseparable part of Artificial intelligence where models are created, and trained in order to create accurate and relevant predictions and decisions for the data that is given to it. Machine Learning models are trained on a set of data which is called a training dataset.
After the model is trained, then the ML model can be used with any other set of data provided to it. The Machine Learning model training process requires a number of steps that need to be followed for the development of ML model training. The steps may include collecting diverse data and cleaning it, training it with adjustment of parameters, validating the results and deploying it into production.
This article includes in-depth knowledge of Machine Learning model training and the processes included in it.
1What is Model Training in ML?
In order to understand Model Training in ML, you will first need to understand that Machine Learning models are feed tons and tons until the parameters of the models adjust and start making to-the-point and accurate predictions.
The data that is used in the model for training purposes Is the called training dataset. And the model's parameters can be described as the values that judge how the model makes the prediction. The main reason for model training is to lessen the errors and decrease the gap or difference between the prediction that model gives and the ground-level truth labels.

In model training, a number of methods can be used. Supervised learning is one method where the model is trained on a label set of data. The second one is the unsupervised method where the data is not labelled but the model makes patterns by the grouping of similar points.
2Types of ML Models
There are multiple types of Machine Learning models and each includes a number of method under them that is explained below:
Supervised learning:
In supervised learning, the model handles a set of labelled data and the labels indicate what is the correct output of the data. It includes further two methods.
- 1. Classification:
Classification involves the prediction of categorical output. For example, making classes of output such as images, or the sentiment analysis of the text given.
- 2. Regression:
Regression is somehow the opposite of classification, In regression, there is a continuous flow of data and the prediction is continuous
Unsupervised Learning
Unsupervised learning is a training learning method for Machine Learning models where the data is not given any of the labels. The model makes use of similar points in order to group them, Here are a few of the unsupervised learning methods:
- 1. Clustering:
In clustering, groups of similar data are created and clusters are formed for the similar data groupings.
- 2. Dimensionality reduction:
This sort of unsupervised learning includes the reduction of data that is not needed by the model to make better and more accurate predictions. The dataset dimensions are lessened down and the model preserves the most relevant and to-the-point information that is sufficient for the model.
3[Training Process] What Are the Steps Involved in Model Training?
Training a Machine Learning model is not at all an easy job to perform. Learning of machines is a time taking process and it requires a corpus of data both for evaluation and training to perform the actual training of Machine Learning models. The Machine Learning model training involves a total of 7 steps. These 7 steps are common in every Machine Learning model training task.
For any model to be trained on any set of data, there are some fundamental steps that need to be followed by the machine learner who is preparing to create the model. There might be some changes within the training process according to the Machine Learning model and the data that is being used in it, but let’s now focus on the common steps that are necessary for model training.
1Data Preparation
The model is trained on a set of data. The more the data, the more the predictions will be correct and the more the model will be relevant. Before even starting model training, make sure that you have a large corpus of data for the model that you are making. The first step in any Machine Learning training will be to gather the data, clean it (meaning to remove the outliers and the errors within the data) and then format it so the model that you are creating should understand I properly.
2Feature Engineering
Feature engineering is something that involves transforming or classifying the data that is more relevant to the model you are training. It means that you make selective use of data and divide them into features to scale them and have a consistent range of values. This won't only help on making the whole process a lot easier, but it will also make the result better.
3Model Selection
This is a crucial part of any Machine Learning model training. It is that main part where you are actually choosing one model out of many to make the correct outcomes and predictions with the data available to you. The model selection can be dependent on multiple factors such as the desired outcome. The current problem, the requirement of output data and etc. You may choose classification over regression just because you want to label your data in order to get a classified response and prediction of the result. This may happen vice versa where you may require a continuous set of data in the outcome and this goes on.
4Model Training
Model training is the core yet most focused part of the overall training steps. In this step, the actual work is carried out. In this step, the iterative work of adjustment of the parameter is carried out until the predictor model or the model is able to provide correct answers to the users.
5Model Evaluation
Once the model is created, then it is moved forward for the evaluation part. In the evaluation of the Machine Learning model, validation is carried out. The dataset on which the validation is carried out is the validation dataset which is extremely important to pass the Quality Check of Machine Learning models. This validation data is all new and it is seen if the mode is up to the mark for the other sets of data. If not, then it moves forwards to the model tuning face if the validation is not up to the mark.
6Model Tuning
When the model evaluation is all right, then it moves forward to the deployment phase. But if the validation doesn’t go well and there are still chances of improvement, then the model training steps take steps towards model tuning. In this tuning, the parameters of the model are tuned in order to look for its performance. Such a kind of tuning of the model is called hyperparameter tuning.
7Model Deployment
When following the steps that start from data collection to model evaluation and model tuning, the last step is to make it work ad move it to production. Once the model is deployed, the model can be used for further data and any new data would work similarly to how it used to work with our test data.
4Important Factors in Model Training
There are several factors that you should consider while training the Machine Learning model. Here are a few of them.
Data: Whenever you select the data for model training, make sure that the data is both quality-wise and quantity-wise ten on ten. The better and large the data will be, the better will be the results from the model.
Model Selection: This is one of the greatest and most critical aspects of model training. Is the model selection. It hugely depends on what you require from the model and what particular task that model has to perform.
Regularization: Regularization is a technique which is used to lessen overfitting. When overfitting happens, the model learns things from the last data pretty well but it is not able to generalize it well to the new data that is given to the model.
Evaluation: The evaluation of the model is done through the validation dataset. This basically tells how well the model reacts to the new data and if the model overfits the data.
Deployment: Once the evaluation is performed and things are working fine with the new or validation data set, then the model training is finally complete and the model is ready to be deployed and moved on to production.
5Productionizing Model Retraining
Once the model is deployed and moved on the production, there still will be space to improve and retrain and it should support continuous improvement and adaption processes. Not only continuous model improvement helps in the accuracy of the outcomes or result, but there is an elevated amount of robustness within the models.
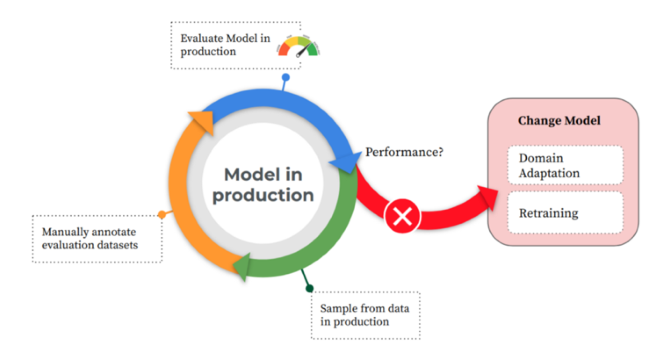
This usually happens when you collect more and more data and make use of a better algorithm. The tuning of the model’s hyperparameters is also beneficial in continuous adaption. When models learn continuously and they adapt with time, it basically means that these models will become more and more flexible.
As more new situations arrive to them, the models will be all-ready to provide customized answers for each user query. The continuous adaption can also be carried out with the help of efficient algorithms and by reducing the amount of data for model training.
This sort of change may bring efficiency to the Machine Learning model that works for certain outcomes. Lastly, the continuous improvement and adaption of the models can reduce the huge cost of training models. In this case, you won't need hardware or software or for the need of human intervention. This reduces the cost to the highest extent.
6Machine Learning Model vs. Algorithm
There is a huge difference between a machine-learning model and an Algorithm. Let’s have a look:
Machine Learning models:
Machine Learning models are representations of the data that is present in the real world. The Machine Learning model makes use of available data to make decision-based data or predictions through consistent training and adjustment of parameters. Once done, the model is capable of producing the predictions for the new data that is put into it.
Algorithm:
It is a step-by-step approach or a process to solve an issue or a problem that you come across. Algorithms can be chosen to train the models of Machine Learning. Or they can use trained models to make predictions.
7Tips for Deep Model Training
If you want to go for deep model training, here are some tips for you:
- 1.Use a diverse and large dataset: As said earlier, the more the data will be, the more excellent the results will be. It should be diverse so the model must be able to generalize well to the new data
- 2.Use a Powerful GPU: If you want to move towards deep model training, then you will need a powerful GPU to speed up the computationally expensive processes.
- 3.Use Pre-Trained Model: A pre-trained model is highly recommended for deep model training. The starting point with a pre-trained model helps in better results and outcomes
8Things to Note
Machine Learning is not an easy thing, It requires lots of hard work as well as tons of training of models to come up with something amazing. Make sure not to take data which is not diverse, and is not quantitative. You will need generalization for the evaluation step of the model training so the more diverse the data is, the better the results are. Apart from that, the usage of regularization techniques is helpful in reducing the overfitting and the repetition of processes. Evaluate the data before moving forward, or else your model may not be up to the mark.







Leave a Reply.